さて、本日は機械学習で行った定期預金申し込み推論結果を Tableau で可視化してみようと思います。機械学習を行うことも難しいのですが、その結果をわかりやすく表示することも多くの方が頭を抱える悩みではないかと思います。Tableau を使えばそんな悩みもすぐに解決するのではないかと思うので、ぜひ一緒に使ってみましょう!
今回使用する機械学習アルゴリズム
今回はランダムフォレストを使用します。
ランダムフォレストは2001年に Leo Breiman によって提案された[1]機械学習のアルゴリズムであり、分類、回帰、クラスタリングに用いられる。決定木を弱学習器とするアンサンブル学習アルゴリズムであり、この名称は、ランダムサンプリングされたトレーニングデータによって学習した多数の決定木を使用することによる。ランダムフォレストをさらに多層にしたアルゴリズムにディープ・フォレストがある。対象によっては、同じくアンサンブル学習を用いるブースティングよりも有効とされる。(出典:Wikipedia)
関連エントリー
興味がある方はぜひ読んでみてください。
www.gis-py.com
www.gis-py.com
今回使用するデータ
2008年から2011年の間のポルトガルの銀行顧客の行動履歴、経済指標と、その顧客が実際に定期預金を申し込んだかどうかの情報を使用します。以下サイトの「 bank-additional-full.csv」を使用します。
archive.ics.uci.edu
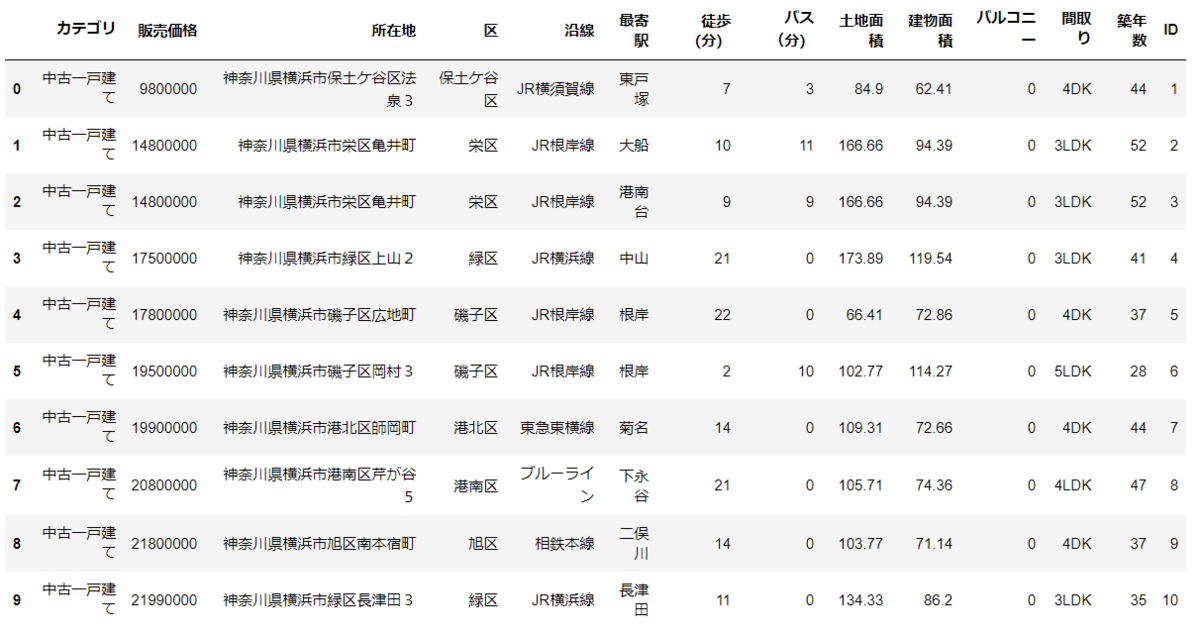
開くとこんな感じになっています。データがすごくきれいに整っているので、加工の必要は無さそうですね。

注意
このデータですが、「;」が区切り文字になっています。色々都合が悪かったので、「,」に変換しました。
フィールド
データに関しては以下を参照してください。全てのフィールドは使用せずに必要なもののみをピックアップして機械学習を行おうと思います。
| フィールド名 |
説明 |
| age |
年齢 |
| job |
職業 |
| marital |
未婚・既婚 |
| education |
教育水準 |
| default |
債務不履行があるか |
| housing |
住宅ローン有無 |
| loan |
個人ローン有無 |
| contact |
連絡方法 |
| month |
最終コンタクト月 |
| day_of_week |
最終コンタクト日 |
| duration |
最終コンタクト時間(秒) |
| campaign |
現キャンペーンにおけるコンタクト回数 |
| pdays |
経過日数:全キャンペーンコンタクト後の日数 |
| previous |
現キャンペーン前のコンタクト回数 |
| poutcome |
前回キャンペーンの成果 |
| emp.var.rate |
雇用変動率 |
| cons.price.idx |
消費者物価指数 |
| cons.conf.idx |
消費者信頼感指数 |
| euribor3m |
欧州銀行間取引金利 |
| nr.employed |
被雇用者数 |
| y |
定期預金申し込み有無 |
環境
Windows10 64bit
Python3.8.5
Tableau Desktop Public Edition 2021.1.0
手順
- データ理解
- モデルの作成
- 推論の実施
1.データ理解
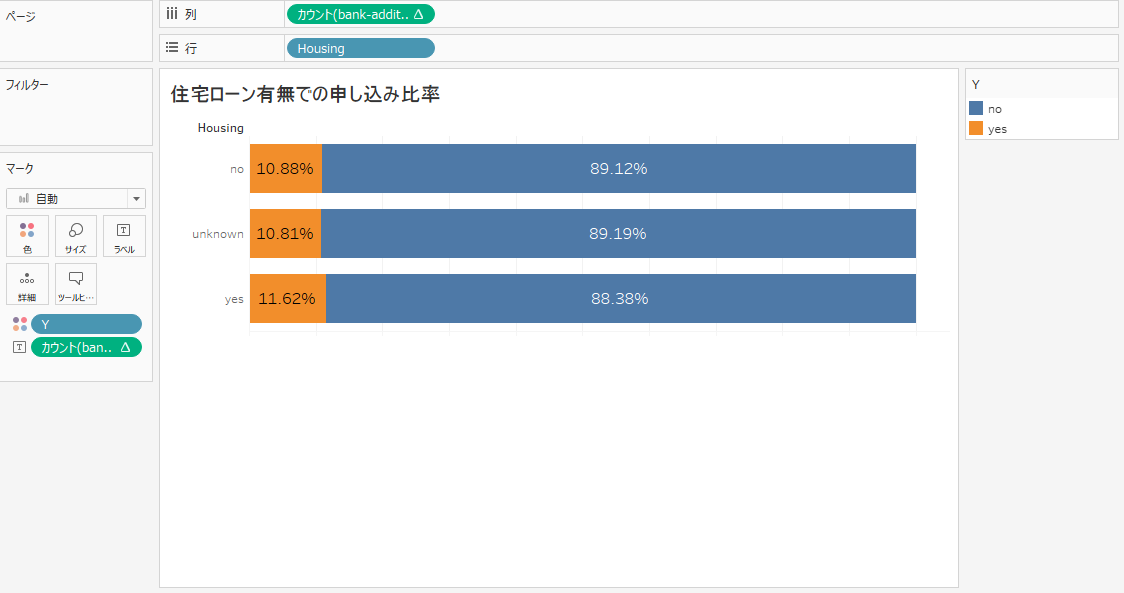
住宅ローン有無ごとの定期預金申し込み比率を確認しましたが、あまり差はなさそうですね。
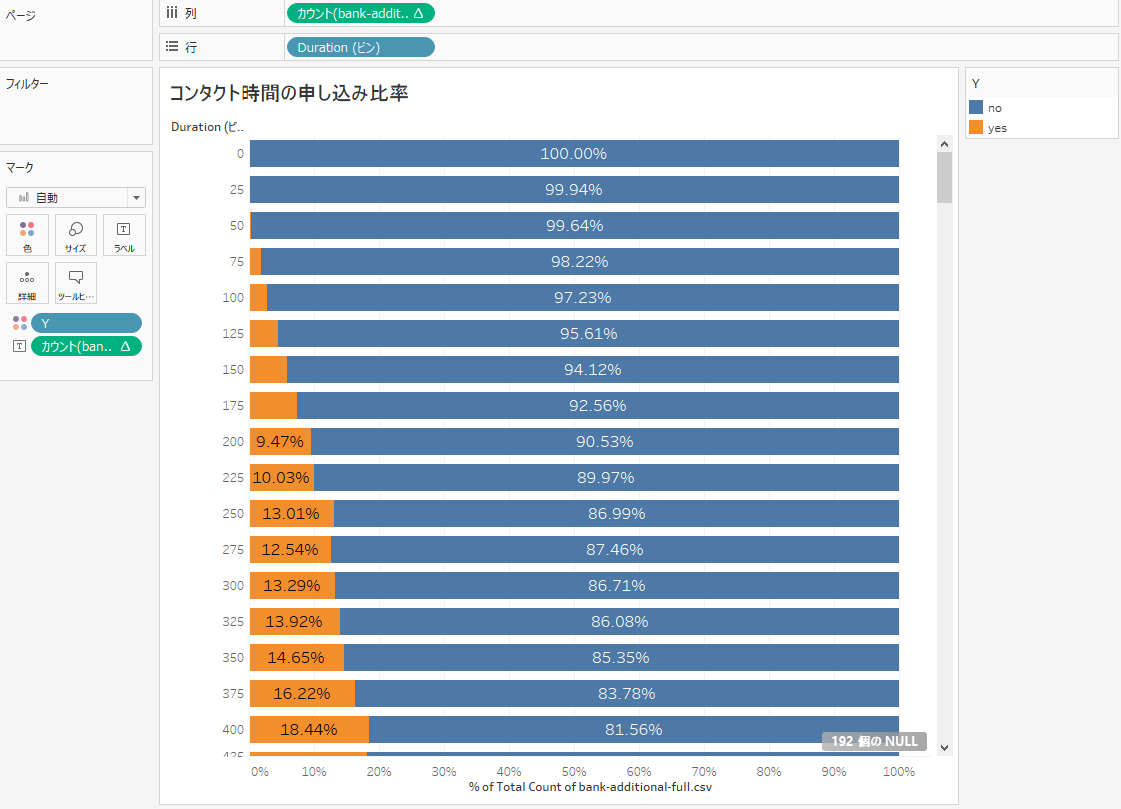
コンタクト時間での申し込み比率を確認しました。コンタクト時間が長くなれば申し込み比率があがることがわかります。
コンタクト回数とコンタクト時間の相関関係を確認します。コンタクト回数が少なくコンタクト時間が長いと申し込みされる傾向にあることがわかります。

2.モデルの作成
上記で確認したデータを使用して学習モデルを作成します。
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
df = pd.read_csv(r"D:\data\machine-learning\bank-additional\bank-additional-full.csv")
y = df["y"]
x = df.iloc[:,0:-1]
x = pd.get_dummies(x)
y = pd.get_dummies(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
forest = RandomForestClassifier(max_depth = 10, n_estimators=50, max_features = 25, random_state=0)
forest.fit(x_train, y_train)
訓練データに対する精度とテストデータに対する精度を確認します。
print(forest.score(x_train, y_train))
print(forest.score(x_test, y_test))
訓練データ「0.9458094590657473」、テストデータ「0.9205593862289987」という結果でした。かなりいい感じだと思います。
ハイパーパラメータの調整
今回使用する RandomForestClassifier に対するパラメータ「max_depth」「 n_estimators」「max_features」ですが、「GridSearchCV」を使用してベストな値を確認しました。
- max_depth・・・一つ一つの木の深さ
- n_estimators・・・ランダムフォレストで使用する決定木の数
- max_features・・・使用する特徴量
from sklearn.model_selection import GridSearchCV
estimator =RandomForestClassifier()
param_grid = {"max_depth": [1,10,25,50],
"n_estimators": [1,10,25,50],
"max_features": [1,10,25,50]}
cv =5
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0)
tuned_model =GridSearchCV(estimator=estimator, param_grid=param_grid)
tuned_model.fit(x_train, y_train)
pd.DataFrame(tuned_model.cv_results_).T
このような表で最適なハイパーパラメータの組み合わせを確認することができます。

ただ、表で確認せずとも best_params_ という値に最適なハイパーパラメータが入っているので、確認してみましょう。
tuned_model.best_params_
以下のような結果になりました。この結果を上記の「モデルの作成」のコードで使用しています。
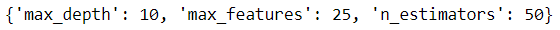
後続の処理で使用するので、best_estimator_ に入っている最適なモデルを引き継ぎましょう。
best_model = tuned_model.best_estimator_
3.推論の実施
作成されたモデルを使って新しいデータに対して推論を実施します。
サンプルデータ作成
推論用にサンプルデータを作成します。
import pandas as pd
df_original = pd.read_csv(r"D:\data\machine-learning\bank-additional\bank-additional-full.csv")
df_original.iloc[:, :] = df_original.iloc[:,:].sample(frac=1).reset_index(drop=True)
df_original.to_csv(r"D:\data\machine-learning\bank-additional\sample.csv")
元データ

サンプルデータ

サンプルデータから予測値を算出、結果をCSVとして出力し、Tableau で結果を確認します。
sample = pd.read_csv(r"D:\data\machine-learning\bank-additional\sample.csv")
sample_x = sample.iloc[:,1:-1]
sample_x = pd.get_dummies(sample_x)
y_new = best_model.predict_proba(sample_x)
a = []
for i in y_new:
for ii in i:
a.append(ii[1])
df_y_new = pd.DataFrame(a, columns=["predict"])
sample_predict = pd.concat([sample,df_y_new],axis=1)
sample_predict.to_csv(r"D:\data\machine-learning\bank-additional\sample_predict.csv")
Tableau で結果を確認
職業別ごとの申し込み確率
admin が申し込み確率が高いことがわかります。

コンタクト時間ごとの申し込み確率
コンタクト時間はおおよそ5分以内にした方がよいことがわかります。

個人ローン有無ごとの申し込み確率
個人ローンを組んでいない顧客の方が申し込み確率が高くなることがわかります。

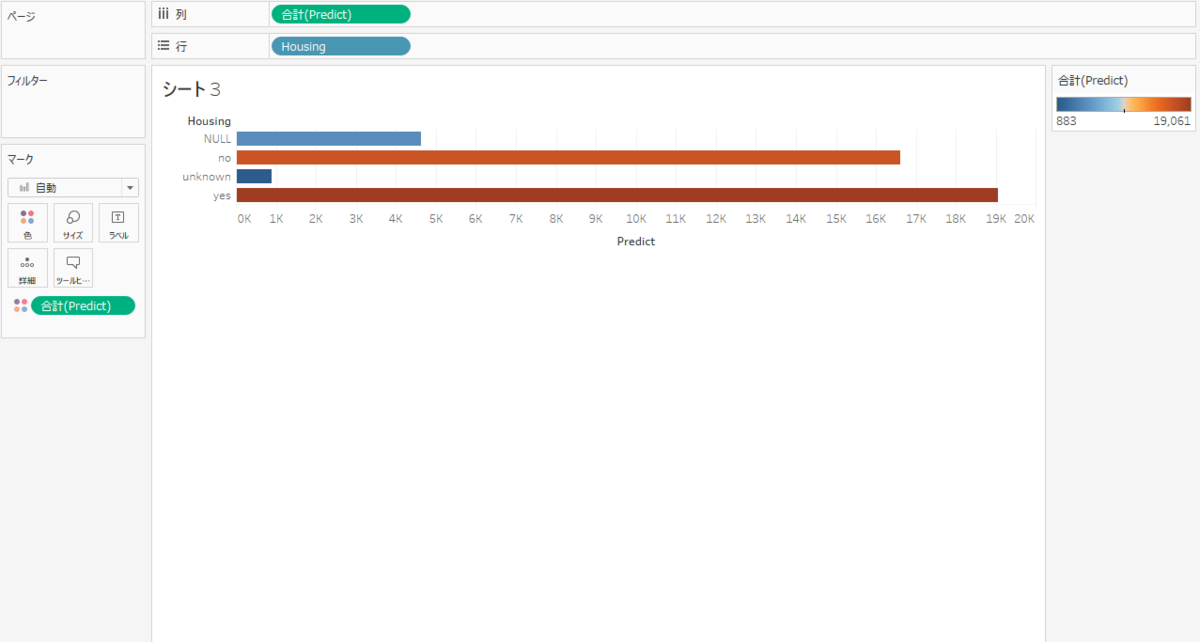
住宅ローン有無ごとの申し込み確率
住宅ローンを組んでいる方がやや申し込み確率が高くなることがわかります。
最終コンタクト月ごとの申し込み確率
なぜか最終コンタクト月が5月だと申し込み確率が高くなっています。興味深いですね。

さいごに
いかがでしたでしょうか。ランダムフォレストを使うことによってかなり高い精度で定期預金申し込みの推論ができたかと思います。ここに詳細な顧客データなどを結合して Tableau で確認してみるともっと面白い結果が見れたのではないかと思います。機械学習については引き続き紹介していきたいと思います。本日は以上です。