さて、本日は Python で PDF を CSV に変換してみようと思います。実は「交通事故統計情報のオープンデータ」を可視化してみようと思ったのですが、そこで使用しようと思ったデータの一部がPDFで公開されており(データ自体はCSVだったのですが、コード表がPDFで公開されていました)、まず最初にPDF → CSV 変換について書いてみようと思いました。
変換対象
「交通事故統計情報のオープンデータ」のコード表ですね。できれば別のフォーマットで公開していただければ手間が省けたのですが・・・
以下のように色々なパターンのページがあることがわかりました。
①コード表説明とコード表
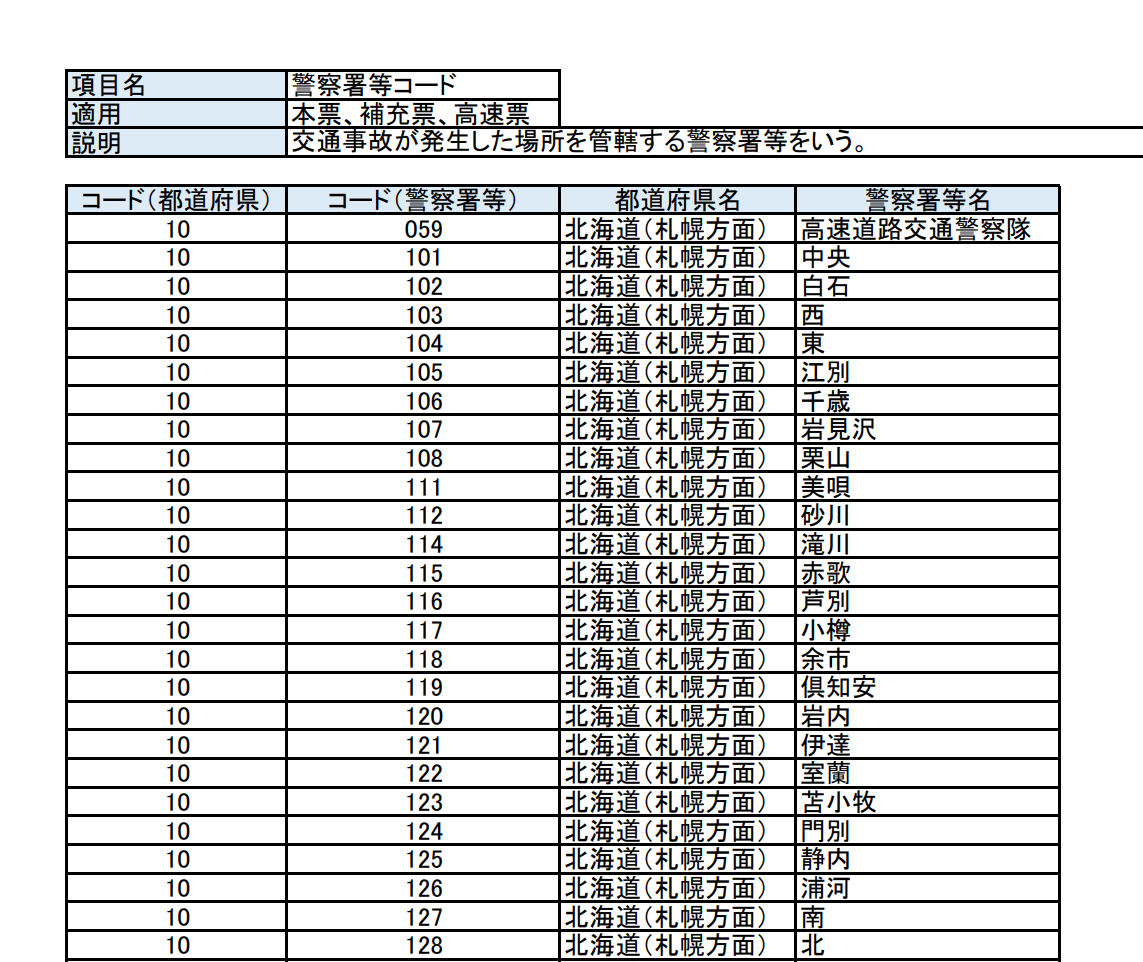
②コード表のみ(コード表が複数ページにまたがっている)

③コード表説明とコード表 とコード表の補足(画面ショット右端の表)

④コード表説明のみ

これらの中から以下をCSV に変換してみようと思います。
- ①のコード表(コード表説明は省く)
- ②のコード表
- ③のコード表(コード表説明は省く)
使用するライブラリ
tabula-py というライブラリを使用します(Python 3.5+必須)。このライブラリを使用することで PDFの表を pandas の データフレームに変換することができます。
※本ライブラリを使用するには Java 8+ が必要なので、こちらもインストールします。
実行環境
Windows10 64bit
Python3.6.6
サンプルコード
「交通事故統計情報のオープンデータ」の各コード表を CSV に変換するサンプルです。
# -*- coding: utf-8 -*- import os import pandas as pd import tabula file_in = r"D:\blog\data\pdf2csv\codebook_2019.pdf" file_out = r"D:\blog\data\pdf2csv\csv" def check_columns(df, previous_df): """前ページと現ページのデータフレーム比較""" difference1 = set(df.keys()) - set(previous_df.keys()) difference2 = set(previous_df.keys()) - set(df.keys()) if (len(difference1) == 0 and len(difference2) == 0): return True else: return False def pds2csv(): """PDF → CSV 変換処理""" df_list = tabula.read_pdf(file_in, lattice=True, pages = 'all') concat_flg = 0 previous_df = "" master_name = "" for df in df_list: # 各コード区分の概要説明の箇所は抽出対象外とする if (df.columns[0] == "項目名"): # 数ページにまたがっているコード表の出力 if (concat_flg == 1): previous_df.to_csv(os.path.join(file_out, master_name + ".csv"), index=False) concat_flg = 0 # 出力ファイル名作成 master_name = df.columns[1] master_name = df[master_name][0].replace('、', '_') + "_" + master_name # 25ページ目の一部表は不要 elif (df.columns[0] == "コード(下1桁)"): pass # 数ページにまたがっているコード表の結合 elif (check_columns(df, previous_df)): df = pd.concat([previous_df, df]) concat_flg = 1 # CSV 出力 else: df.to_csv(os.path.join(file_out, master_name + ".csv"), index=False) concat_flg = 0 previous_df = df if __name__ == '__main__': pds2csv()
結果を確認するとこのようにCSV が作成されたことがわかりました。

中身も問題なさそうですね。全部のファイルは調べていないのですが、とりあえず変換はできたっぽいです(もし何か不備がありましたら本エントリーにコメントをいただけると助かります)。

さいごに
PDF に記載されている内容を CSV に変換したいというケースはけっこうあると思います(特にオープンデータまわりを触ることが多い方)。そんな時に tabula-py はとても便利な存在かと思います。興味のある方はぜひ使ってみてください。PDF から CSV の変換が終わったのでさっそく「交通事故統計情報のオープンデータ」の可視化にとりかかりたいところですが、その前に今回変換した CSV を DB に格納するなど何かしらの処理が必要な気がしています。なので次回は その辺について書いてみようと思います。