さて、本日は 「SUUMO の中古物件情報を Tableau で分析してみる ~データ予測編~」です。データ収集編で SUUMO の情報をスクレイピング、データ分析編でその情報の分析をしましたが、今回は機械学習を使って販売価格の予測を行ってみようと思います。
なお、本シリーズは以下3エントリーにわたって SUUMO の中古物件情報を扱います。本エントリーはデータ予測編です。
使用する機械学習アルゴリズム
ランダムフォレストを使用します。以下エントリーでもランダムフォレストを使用していますが、この時は分類で使用しました。今回は回帰で使用します。
関連エントリー
興味がある方はぜひ読んでみてください。
使用するデータ
- データ収集編で作成した property.csv
データ を加工
処理の都合上、以下加工を行います。
- ID 列追加
- 販売価格列を一番最後に移動
- ㎡ をを空白に置換(データ収集時に取り切れてなかったものがあったようです・・・)
- 徒歩(分)、バス(分)が空白なレコードを削除
- バルコニーが空白な場合、0に置換

フィールド
販売価格以外を学習に使用します。
| フィールド名 | 説明 |
|---|---|
| カテゴリ | 中古マンション or 中古一戸建て |
| 販売価格 | 販売価格 |
| 所在地 | 物件所在地 |
| 区 | 区 |
| 沿線 | 物件最寄沿線 |
| 最寄駅 | 物件最寄駅 |
| 徒歩(分) | 物件から最寄駅までの徒歩時間。バスの場合は物件からバス停までの時間 |
| バス(分) | バス乗車時間。バスを使用しない場合は0 |
| 土地面積 | 土地面積。中古マンションは建物面積=土地面積とする |
| 建物面積 | 中古一戸建てもしくは中古マンションの建物面積 |
| バルコニー | バルコニー面積。中古マンションのみ使用 |
| 間取り | 物件の間取り |
| 築年数 | 築年月から計算 |
予測するフィールド
販売価格を予測して、実際のデータと比較してみようと思います。
- 販売価格
手順
- データ理解
- モデルの作成
- モデルの評価
環境
Windows10 64bit
Python3.8.5
Tableau Desktop Public Edition 2021.1.0
1.データ理解
販売価格を一億円以下に絞って確認します(その方がわかりやすいので)。
区ごとの販売価格分布
中古マンション
港北区の販売価格分布がやや高いことがわかります。

中古一戸建て
都筑区の販売価格分布が高いことがわかります。

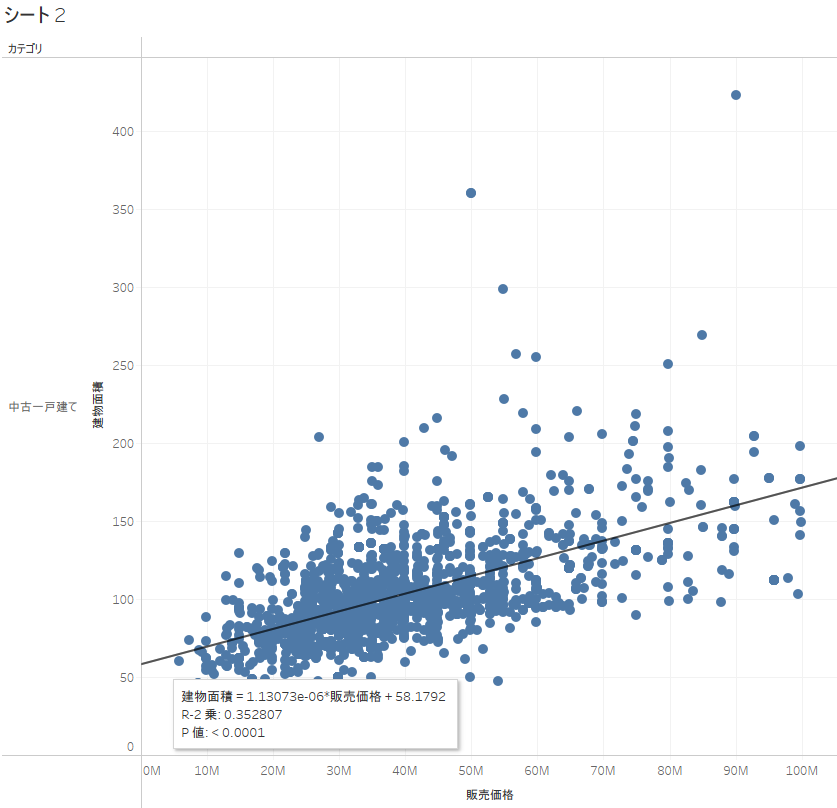
建物面積と価格の散布図
中古マンション
あまり相関関係がないですね。

中古一戸建て
こちらもあまり相関関係がないですね。
築年数と価格の散布図
中古マンション
やや負の相関がありますね。

中古一戸建て
こちらはほとんど相関がないことがわかります。単純に築年数が高いと価格が安くなるとは言えないですね。

2.モデルの作成
以下のようにモデルを作成しました。
import pandas as pd from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import train_test_split # データ読込 df = pd.read_csv(r"D:\data\csv\property.csv") df = df.astype({'建物面積': 'float64'}) # 出力変数 y = df["販売価格"] # 入力変数 x = df.iloc[:,0:-1] # ダミー変数化 x = pd.get_dummies(x) y = df["販売価格"] x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=50) # モデル作成 rfr = RandomForestRegressor(n_estimators=100) model = rfr.fit(x_train, y_train)
訓練データに対する精度とテストデータに対する精度を確認します。
print(model.score(x_train, y_train)) print(model.score(x_test, y_test))
訓練データ「0.9634692855923855」、テストデータ「0.9631908599251336」という結果でした。かなりいい感じだと思います。

予測値の計算
作成したモデルを使用して価格を推論します。
predict = model.predict(x)
predict = pd.DataFrame(predict, columns=["predict"])
predict.head()
このように価格が推論されました。

CSVを読み込んだデータフレームの右端に推論結果を追加します。
results = pd.concat([df,predict],axis=1)
results.head()
この結果をCSVで出力してTableau で確認します。

3.モデルの評価
予測値と実際の販売価格を比較して誤差の確認を行います。
「誤差」フィールド作成

推論値と実際の価格の散布図
推論値をX軸に、実際の価格をY軸にして散布図を書きます。おおむねY=Xの線上に分布しているようですね。これは推論が的中していることを示します。
中古マンション

中古一戸建て

区別誤差の分布
中古マンション
誤差の分布はかなり狭いですね。

しかし、一部のデータで大きく誤差が出ているものもあります。


中古一戸建て
こちらも誤差の分布はかなり狭く、中古マンションと同じように一部のデータで大きく誤差が出ていました。

沿線別誤差の分布
中古マンション
誤差の分布はかなり狭いですね。

中古一戸建て
こちらはみなとみらい線にやや大きな分布がみられますね。

さいごに
本シリーズ最後のエントリーでしたが、いかがでしたでしょうか。一部のデータを除き実際の価格と予測値の誤差はかなり小さい結果になりました(それでも数十万円~300万円くらいの誤差が出ているものも多かったですが)。学習に使用するデータをもう少し精査することによってより精度の高い結果が出るかと思いますが、その辺は色々勉強していきたいと思います。本日は以上です。