さて、本日は機械学習ですね。今までのエントリーと異なりデータを加工・可視化するのではなく、収集したデータを使って将来の予測値を可視化してみようと思います。
機械学習とは
機械学習(きかいがくしゅう、英: Machine Learning)とは、経験からの学習により自動で改善するコンピューターアルゴリズムもしくはその研究領域で[1][2]、人工知能の一種であるとみなされている。「訓練データ」もしくは「学習データ」と呼ばれるデータを使って学習し、学習結果を使って何らかのタスクをこなす。例えば過去のスパムメールを訓練データとして用いて学習し、スパムフィルタリングというタスクをこなす、といった事が可能となる。(出典:Wikipedia)
今回使用する機械学習ライブラリ
今回は scikit-learn を使おうと思います。かなり広く使われているライブラリのようで、おそらく私のような初学者はまずこれを使うのがいいのではないかと思います。
今回使用するデータ
不動産取引価格ダウンロード 国土交通省のデータを使用します。
2010年~2020年の横須賀市のデータをダウンロードしてみます。
データはこんなイメージですね。
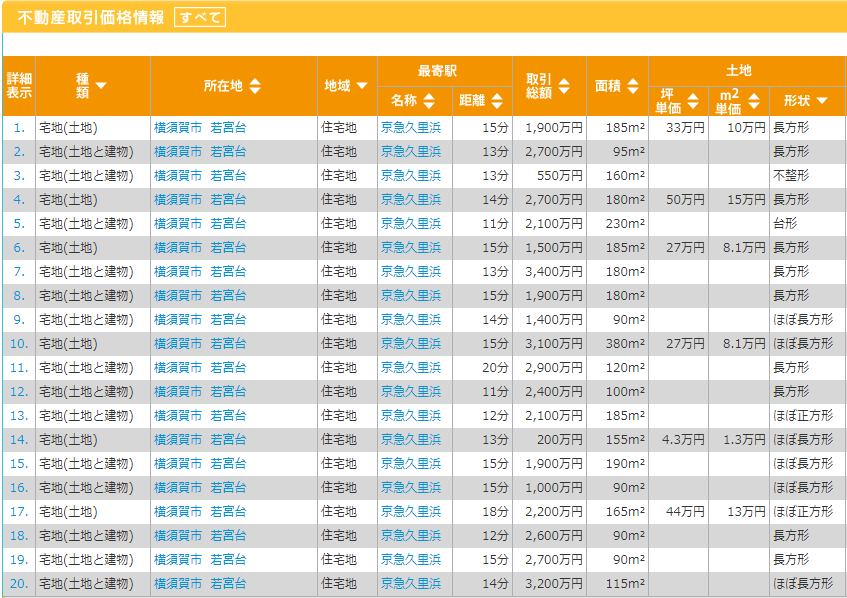
各フィールド
データに関しては以下を参照してください。全てのフィールドは使用せずに必要なもののみをピックアップして機械学習を行おうと思います。
| フィールド名 | 説明 |
|---|---|
| No | 連番 |
| 種類 | 「宅地(土地)」「中古マンション等」など。今回は「宅地(土地と建物)」を利用する。 |
| 地域 | 「住宅地」「商業値」など。 今回は「住宅地」を利用する。 |
| 市区町村コード | 市区町村コード |
| 都道府県名 | 都道府県名 |
| 市区町村名 | 市区町村名 |
| 地区名 | 地区名 |
| 最寄駅:名称 | 物件の最寄駅名 |
| 最寄駅:距離(分) | 物件から最寄駅までの距離(分) |
| 取引価格(総額) | 物件の取引価格。これが今回推論したい値。 |
| 坪単価 | 坪単価 |
| 間取り | 間取り |
| 面積(㎡) | 面積(㎡) |
| 取引価格(㎡単価) | 取引価格(㎡単価) |
| 土地の形状 | 「長方形」「不整形」など |
| 間口 | 間口 |
| 延床面積(㎡) | 延床面積(㎡) |
| 建築年 | 建築年。元号表記。 |
| 建物の構造 | 「SRC」「木造」など |
| 用途 | 「住宅」「共同住宅」など |
| 今後の利用目的 | 「住宅」「事務所」など |
| 前面道路:方位 | 前面道路の方位 |
| 前面道路:種類 | 前面道路の種類 |
| 前面道路:幅員(m) | 前面道路の幅員(m) |
| 都市計画 | 「商業地域」「第1種中高層住居専用地域」など |
| 建ぺい率(%) | 建ぺい率(%) |
| 容積率(%) | 容積率(%) |
| 取引時点 | 「2016年第3四半期」など |
| 改装 | 改装済みか否か |
| 取引の事情等 | 特筆事項。「瑕疵有りの可能性」など |
環境
Windows10 64bit
Python3.8.5
Tableau Desktop Public Edition 2021.1.0
手順
- 横須賀市各駅の位置情報取得
- データ加工
- 「種類」フィールドの値が「宅地(土地と建物)」のデータのみ使用
- 「地域」フィールドの値が「住宅地」のデータのみ使用
- 「用途」フィールドの値が「住宅」のデータのみ使用
- 今回推論に使用するフィールドにNULLがあるレコードの除去
- 「築年数」(元号表記)から築年数を算出
- 「築年数」(元号表記)から不正な値(「戦前」)を昭和15年に置換する
- 「最寄駅:距離(分)」の不正な値(「1H30?2H」など)を分に変換
- 「最寄駅:名称」の「逗子・葉山」を「逗子」に置換
- 外れ値の除去(1億5000万円より高い物件は今回は除去)
- 外れ値の除去(延床面積(㎡)が250㎡より大きいレコードは削除)
- モデルの作成
- モデルの評価
1.横須賀市各駅の位置情報取得
こちらのサイトのデータを利用し CSV を作成しました。(鎌倉や逗子が入っているというツッコミはなしでお願いします・・・)
2.データ加工
以下のコードで「手順」に記載した加工をすべて行っています。
import os import pandas as pd # 使用するファイル input_dir = r"D:\blog\data\property" property_data = "14201_20101_20204.csv" # 出力するファイル output_data = "output_data.csv" # CSV読込 df = pd.read_csv(os.path.join(input_dir, property_data), encoding="cp932") # 「種類」フィールドの値が「宅地(土地と建物)」のデータのみ使用 df = df[df['種類'] == "宅地(土地と建物)"] # 「地域」フィールドの値が「住宅地」データのみ使用 df = df[df['地域'] == "住宅地"] # 「用途」フィールドの値が「住宅」を含むデータのみ使用 df = df[df['用途'].str.contains("住宅") == True] # 欠損値除去 df = df.dropna(subset=["最寄駅:距離(分)","延床面積(㎡)","建築年","建物の構造",'地域','用途']) # 連番付与 serial_num = pd.RangeIndex(start=1, stop=len(df.index) + 1, step=1) df["ID"] = serial_num # 不要なフィールドを削除 df = df[["ID", "最寄駅:名称","最寄駅:距離(分)","延床面積(㎡)","建築年","建物の構造","取引価格(総額)"]] # 最寄駅:距離(分)の不正な値を置換 df = df.replace({'最寄駅:距離(分)': {"1H?1H30": 60}}) df = df.replace({'最寄駅:距離(分)': {"1H30?2H": 90}}) df = df.replace({'最寄駅:距離(分)': {"2H?": 120}}) df = df.replace({'最寄駅:距離(分)': {"30分?60分": 30}}) # 建築年の不正な値を置換 df = df.replace({'建築年': {"戦前": "昭和15年"}}) # 建築年の元号表記を築年数に変換 df['年号'] = df['建築年'].str[:2] df['和暦_年'] = df['建築年'].str[2:].str.replace('年','').astype(int) df.loc[df['年号']=='昭和','築年数'] = 2021 - (df['和暦_年'] + 1925) df.loc[df['年号']=='平成','築年数'] = 2021 - (df['和暦_年'] + 1988) df.loc[df['年号']=='令和','築年数'] = 2021 - (df['和暦_年'] + 2019) #「最寄駅:名称」の「逗子・葉山」を「逗子」に置換 df = df.replace({'最寄駅:名称': {"逗子・葉山": "逗子"}}) # 外れ値の除去(取引価格(総額)が1億50000万円より大きいレコードは削除) df = df[df['取引価格(総額)'] <= 150000000] # 外れ値の除去(延床面積(㎡)が250㎡より大きいレコードは削除) df = df[df['延床面積(㎡)'].astype(int) <= 250] # データの加工結果を出力 df.to_csv(os.path.join(input_dir, output_data))
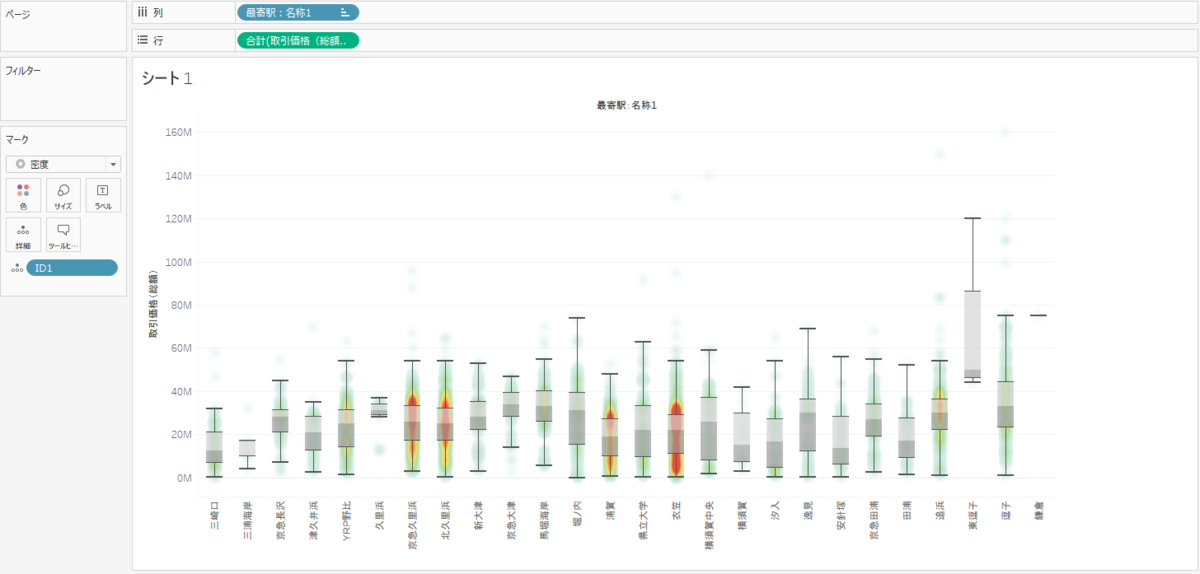
出力した CSV を Tableau で確認してみます。各駅の取引価格(総額)を箱ひげ図で表示してみました。駅の順番はあやしいですが、「三崎口」や「三浦海岸」など三浦半島の先端に行くにしたがって金額が低くなることがわかります。また、サンプル数が少ないのですが、「逗子」や「鎌倉」は金額が高いですね。高級住宅街などがあるせいでしょうか。
価格と広さの関係性を確認してみようと思います。
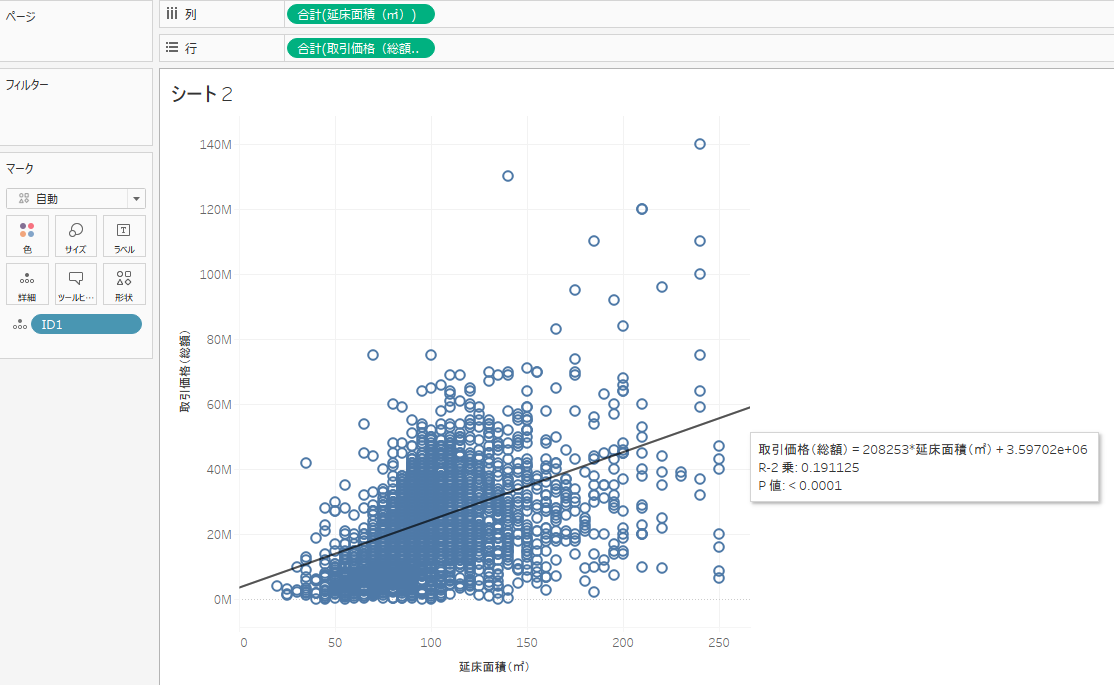
R2乗値が約0.19ということは価格と広さにはあまり相関関係がないと言えそうです。
次に価格と築年数の関係性を確認してみようと思います。

R2乗値を見る限り、築年数が大きければ価格が下がる傾向にあると言えそうです。
また、「1.横須賀市各駅の位置情報取得」で作成した CSV を Tableau で読み込んでみました。
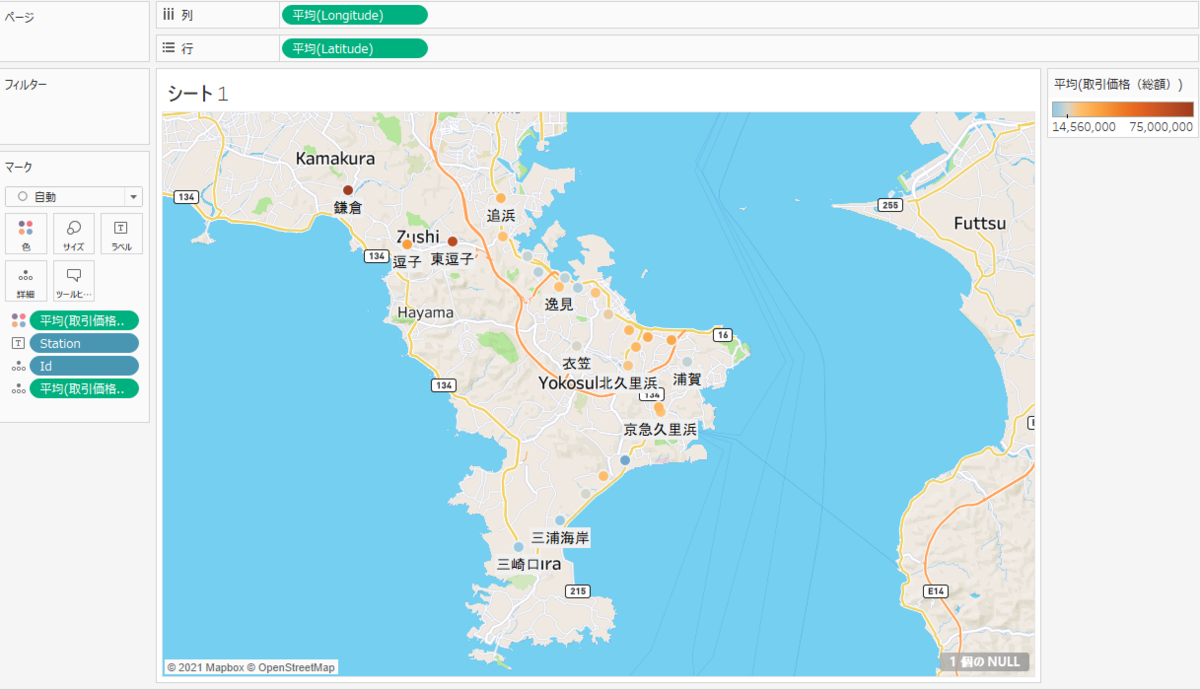
「取引価格(総額)」が高いほどポイントが赤色になるように設定しました。「逗子」や「鎌倉」エリアが高いことがわかります。
3.モデルの作成
まずは学習に必要なフィールドのみを抽出します。また、「1.横須賀市各駅の位置情報取得」で作成した CSV の緯度経度情報を output_data.csv にマージします。
import pandas as pd import numpy as np # 使用するファイル input_dir = r"D:\blog\data\property" output_data = "output_data.csv" station_master = "yokosuka_station_master.csv" # 前の手順で出力した CSV の読込 df_output = pd.read_csv(os.path.join(input_dir, output_data), encoding="utf-8") # 駅マスタ読込 df_station = pd.read_csv(os.path.join(input_dir, station_master), encoding="utf-8") # マージ df = pd.merge(df_output, df_station, left_on='最寄駅:名称', right_on='station') df = df.drop(["id", "station"], axis=1) df.reset_index(drop=True, inplace=True) # 出力変数 t = df["取引価格(総額)"] # 学習に必要なカラムを抽出 x = df.iloc[:,[1,2,3,5,9]] x.head()
ちなみに カラム抽出前のデータフレームは以下のように駅マスタの緯度経度が追加されています。
df.head()

object 型のカラムをダミー変数化します。
x = pd.get_dummies(x) x.head()
データを訓練データと検証データに分割してモデルの学習を行います。
from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression # 訓練データと検証データに分ける x_train, x_val, t_train, t_val = train_test_split(x, t, test_size = 0.3, random_state = 0) # 線形回帰モデル model = LinearRegression() model.fit(x_train, t_train)
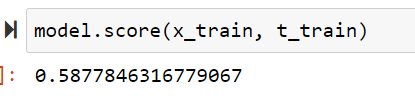
モデルの評価を行います。訓練データで決定係数を確認しましたが、あまりいい値ではないですね。。
model.score(x_train, t_train)
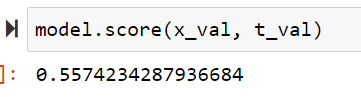
検証データでも決定係数を確認してみます。
model.score(x_train, t_train)
予測値の推論
とりあえず今回は精度向上の試みはせずに先に進めようと思います。生成されたモデルを使って全てのデータの入力変数を使用して価格を推論します。
# 価格推論 pred = model.predict(x) # 列名付与 y = pd.DataFrame(pred, columns=["predict"]) # 読み込んだ CSV の右端に推論結果を追加 results = pd.concat([df, y], axis=1) # CSV 出力 results.to_csv(r"D:\blog\data\property\predict.csv", index=False)
4.モデルの評価
推論した価格と実際の価格を比較して誤差がどの程度かを Tableau で確認してみようと思います。
推論価格をX軸に、実際の価格をY軸にして散布図を作ってみました。本来は斜め45度のに分布するのが良いのですが、結果を見るとうーん、といった感じですね。
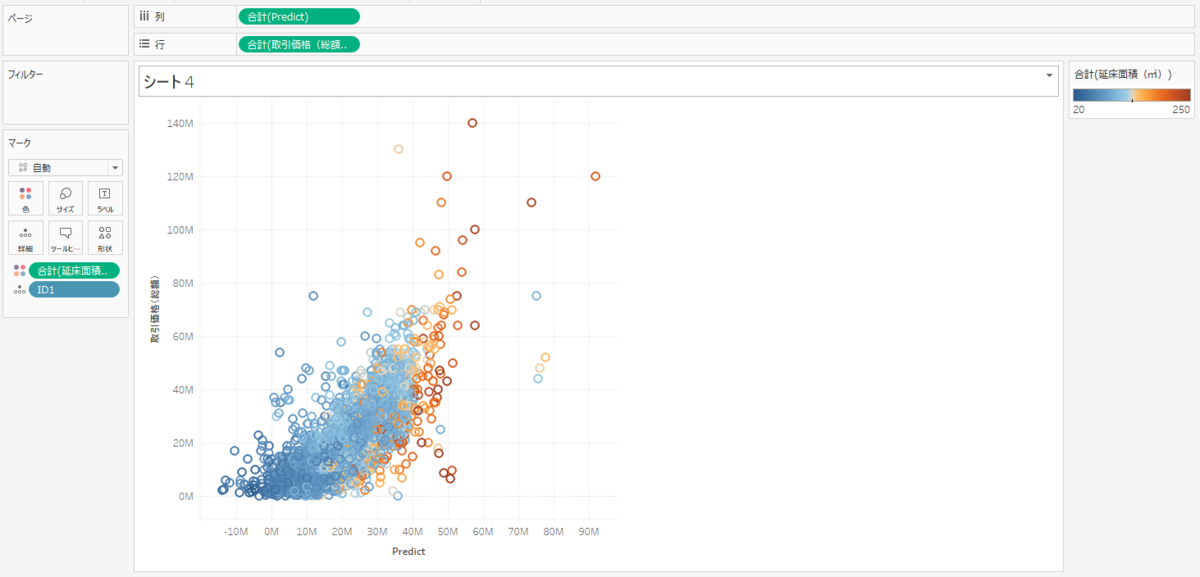
このように推論値がマイナスになっているものもあり、マイナスはいかんだろう感じです(笑)
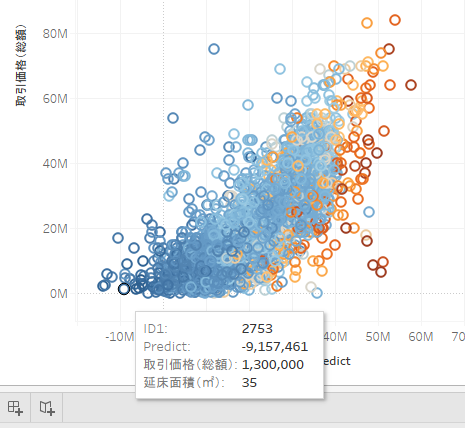
他のを見ても推論値と実際の値とのずれが大きいことがわかります。
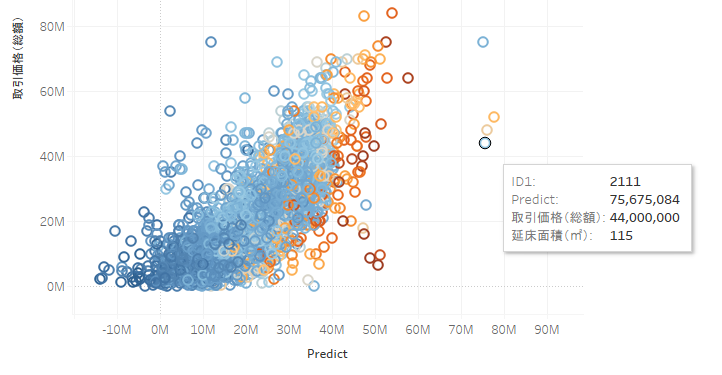
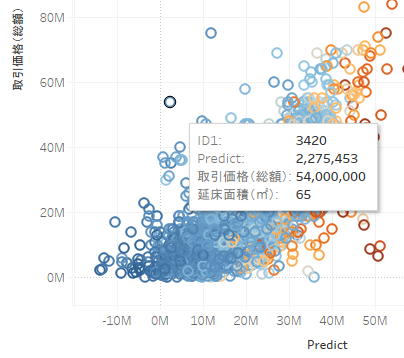
中にはかなり惜しいものもありますね。
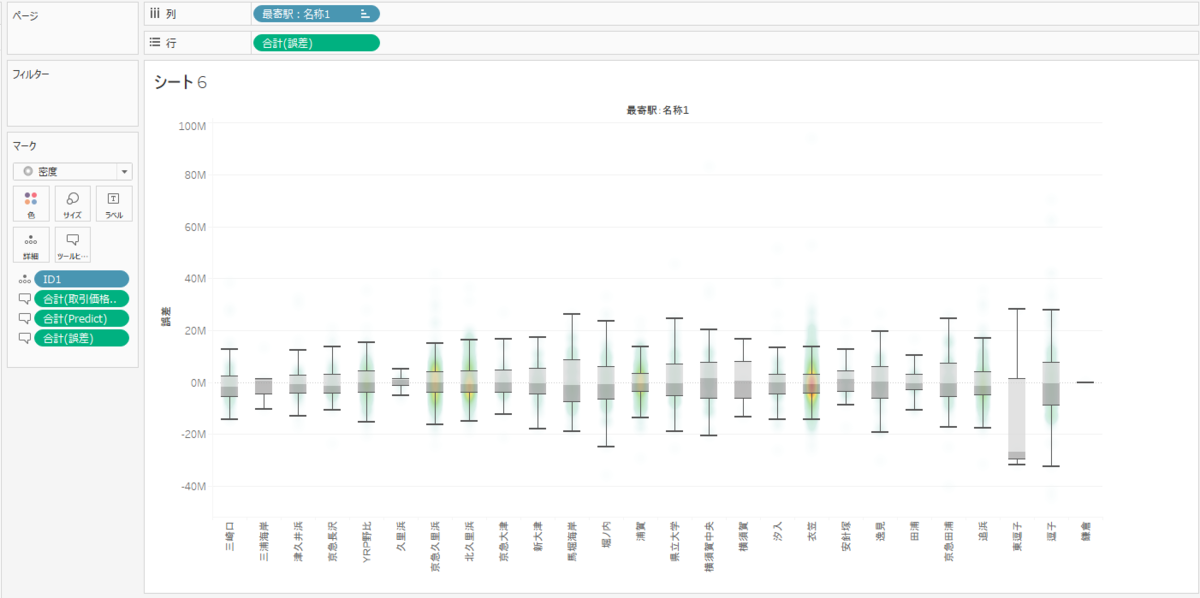
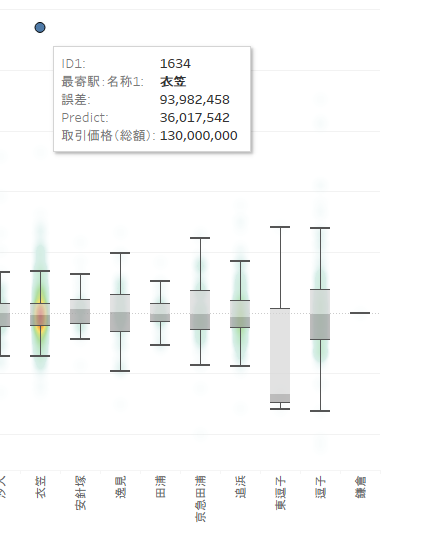
「誤差」フィールドを作成して各駅ごとの推論値と実際値の誤差を表示してみました。「三浦海岸」「久里浜」「鎌倉」あたりが誤差が少ないことがわかります。
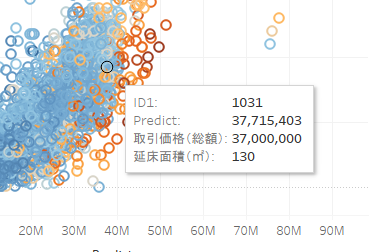
外れ値を確認してみると誤差が9千万以上ありますね。これはあまりいい結果とは言えないですね・・・
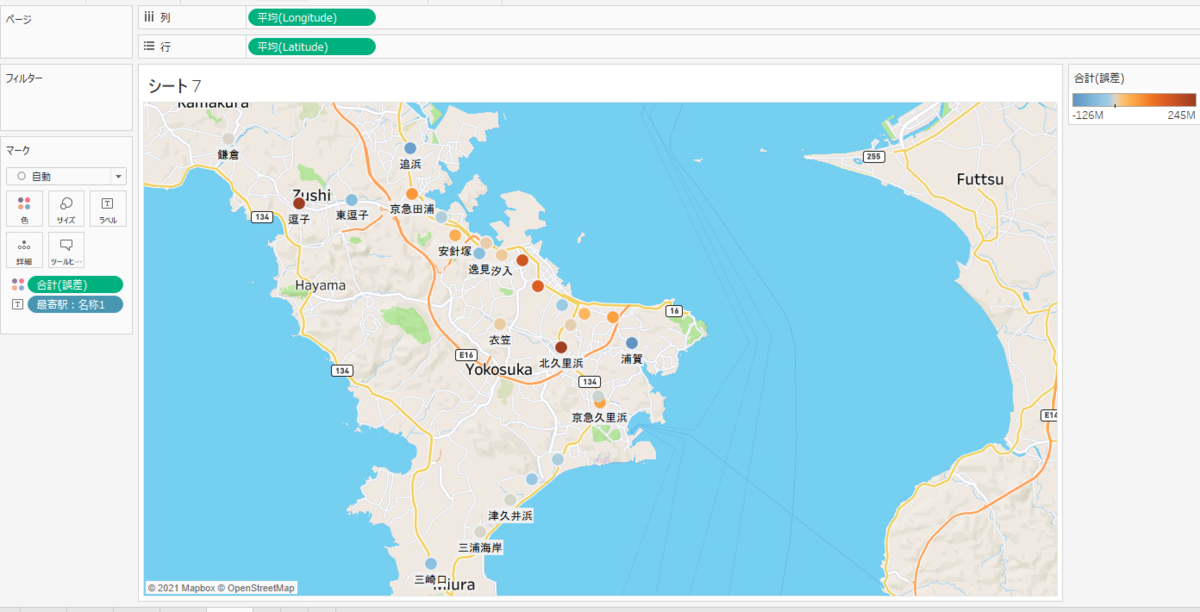
地図上で確認してみます。グレーになっているポイント(「三浦海岸」「久里浜」「鎌倉」など)が誤差が少ない駅ですね。
さいごに
はじめて本ブログで機械学習について触れてみましたがいかがでしたでしょうか。結果はいまいちでしたが、もう少しデータを詳細に分析し適切な学習モデルを作成することでより正確な推論値を得ることができるかと思います。これからの時代はただデータを GIS 上で可視化するだけでは差別化を行うことは難しく、機械学習などを用いて将来の予測値などを可視化する必要があるかと思っています。自分自身学ばなければならないことが多いのですが、時間をかけて学習する価値はあるかと思っています。これからも機械学習について継続的に本ブログで紹介しようかと思いますのでよろしくお願いします。本日は以上です。