さて、本日は交通事故統計データの可視化をしてみようと思います。本エントリーですが、以下二つのエントリーで行った作業を前提として進めていきます。興味がありましたらぜひ以下エントリーも読んでみてください。
www.gis-py.com
www.gis-py.com
交通事故統計データとは
警察庁が公開しているオープンデータです。その名の通り交通事故の統計データですね。
www.npa.go.jp
交通事故統計データ概要
2019年の交通事故統計データが公開されています。こちらに記載されていますが、以下三つのデータが CSV 形式で存在します。
本票
- 交通事故1件につき1レコード
- 記録事項は、交通事故の内容に関する事項及び交通事故に関与した者(当事者A、当事者B)に関する事項
補充票
- 本票以外の交通事故に関与した者1人について1レコード
- 記録事項は、本票に記録されない交通事故に関与した者のうち、死亡若しくは負傷した者又は車両等の運転者で死傷がなく死亡事故に関与した者に関する事項
高速票
- 高速自動車国道及び道路交通法第110条第1項により国家公安委員会が指定する自動車専用道路における交通事故1件について1レコード
- 記録事項は、交通事故の発生地点、道路構造等に関する事項
要するに本票がメインのレコードで補充票、高速票がそれに紐づくレコードといった感じでしょうか。今回は「本票」「高速票」のデータを使用して可視化を行いたいと思います。補充票に関しては可視化はしませんが、一応データの格納だけはしようと思います。
手順
- 本票、補充票、高速票を SQLite に格納する
- 本票のデータを加工
- 加工したデータからシェープファイルに変換するデータを取得
- PyShp を使ってポイントのシェープファイルを作成
- 作成したシェープファイルを ArcGIS Online で可視化する
PyShp と ArcGIS Online に関しては以下のエントリーで紹介しているので、興味のある方がいましたらぜひ読んでみてください。
www.gis-py.com
www.gis-py.com
実行環境
Windows10 64bit
Python3.6.6
ArcGIS Online
手順1(本票、補充票、高速票を SQLite に格納) サンプルコード
まずは データを SQLite に格納します。前回エントリーと同じ要領ですね。
import sqlite3
from os.path import join, split
from glob import glob
import pandas as pd
csv_path = r"D:\blog\data\csv"
db_path = r"D:\blog\data\sqlite\test.db"
def insert_csv():
csv_files = glob(join(csv_path, "*.csv"))
for csv in csv_files:
table_name = split(csv)[1]
table_name = table_name[0:-4]
df = pd.read_csv(csv, dtype=object, encoding="SHIFT-JIS")
with sqlite3.connect(db_path) as conn:
df.to_sql(table_name, con=conn)
if __name__ == '__main__':
insert_csv()
前回エントリーで作成したDBに「hojuhyo_2019」「honhyo_2019」「kosokuhyo_2019」というテーブルが追加されました。
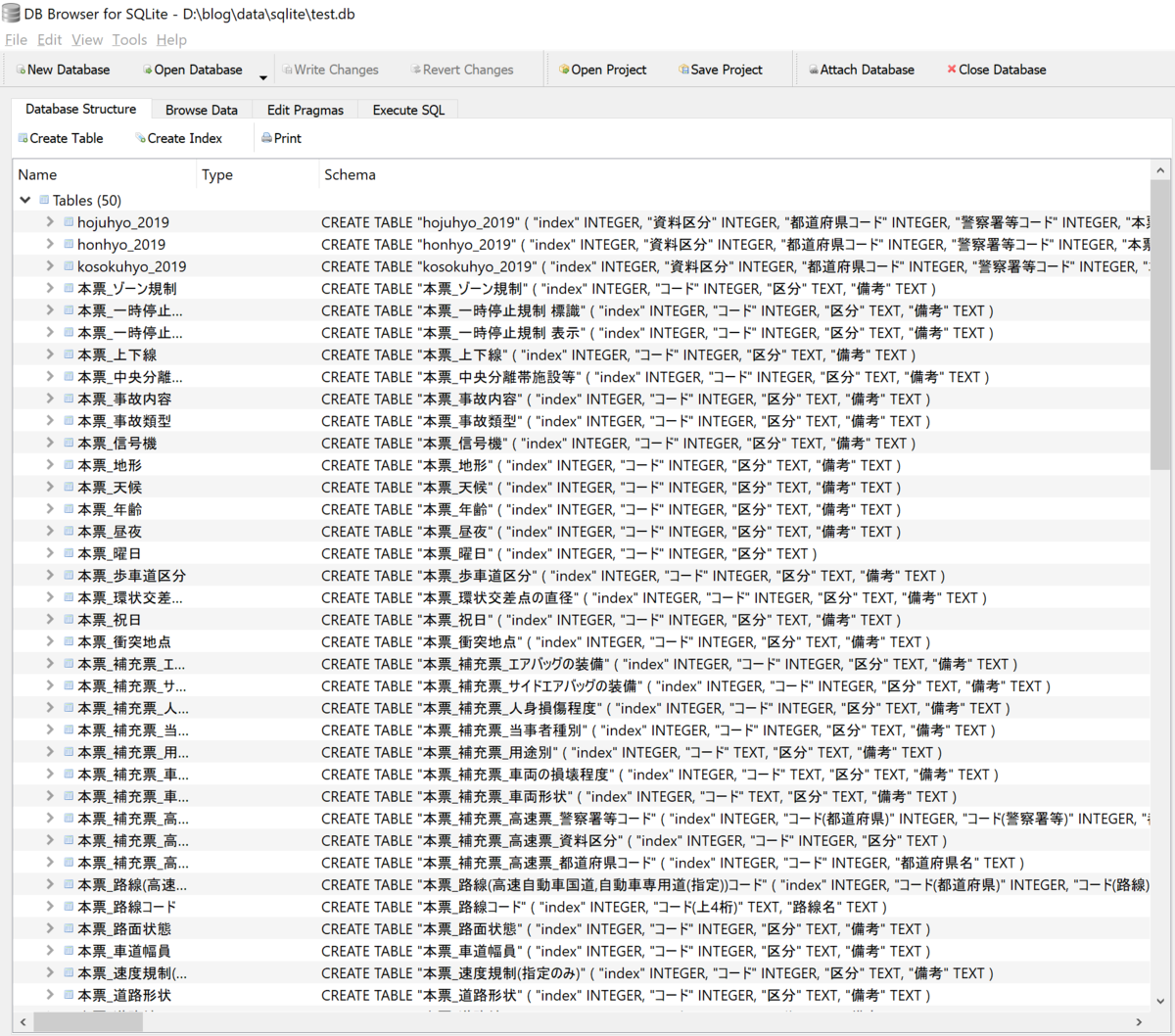
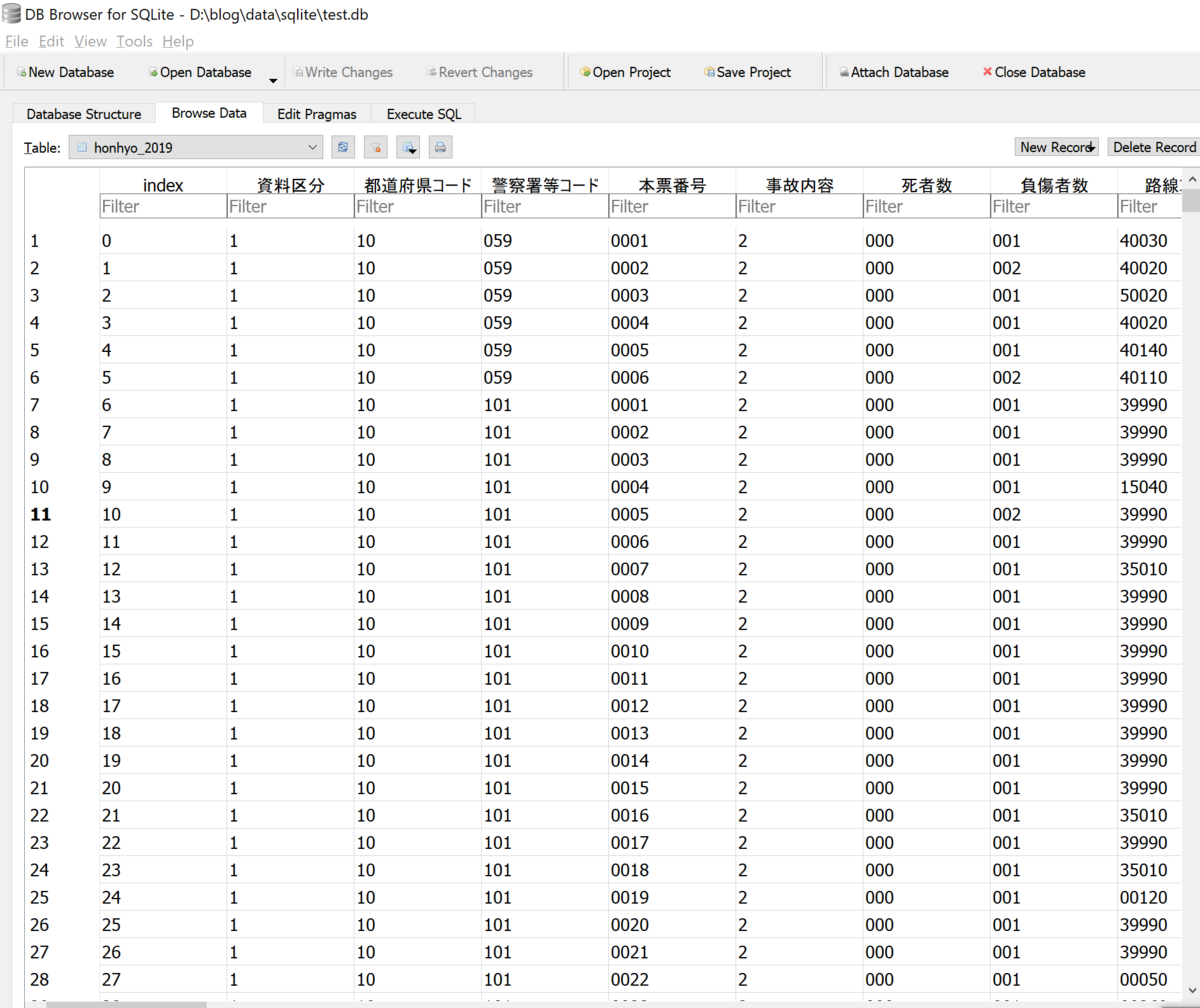
手順2(手順「1」で格納した本票のデータを加工) サンプルコード
オープンデータにありがちですが、公開されているデータがあまりきれいな状態ではなく、少しデータの整形をしたいと思います。ここのパートはややこしく、説明がわかりづらいかもしれませんがご容赦ください。以下3つのステップを踏んでデータ加工を行います。
- 「honhyo_2019」テーブルの「死者数」、「負傷者数」カラムに入っている不要な0を削除
- 一意になるキーを作成
- 「honhyo_2019」テーブルの「路線コード」カラムを名称に変換
1.「honhyo_2019」テーブルの「死者数」、「負傷者数」カラムに入っている不要な0を削除
負傷者が一人だったら、001のような値が入っているのですが、このような形でデータが格納されているのは一体なぜなのでしょうか。ちょっとよくわからないですね。。。
update honhyo_2019
set 死者数 = case
when substr(死者数,1,2) = '00' then
substr(死者数,3,1)
when substr(死者数,1,1) = '0' and substr(死者数,2,1) <> '0' then
substr(死者数,2,2)
end,
負傷者数 = case
when substr(負傷者数,1,2) = '00' then
substr(負傷者数,3,1)
when substr(負傷者数,1,1) = '0' and substr(負傷者数,2,1) <> '0' then
substr(負傷者数,2,2)
end
加工前
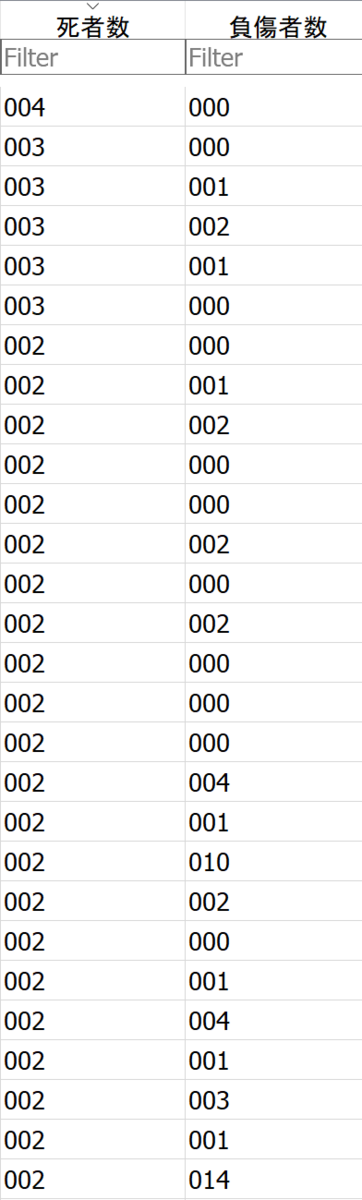
加工後
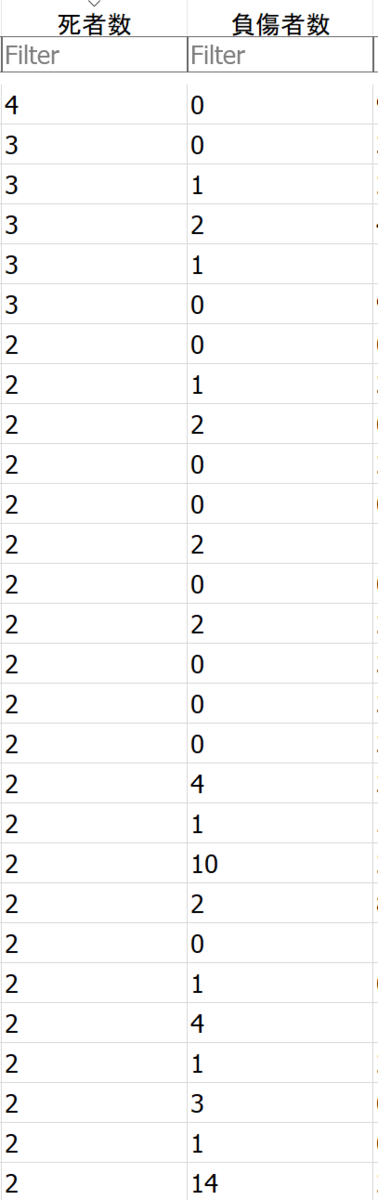
2.一意になるキーを作成
本票番号というカラムがキーになると思ったのですが、色々調べてると違うことがわかりました。。。「honhyo_2019」「kosokuhyo_2019」テーブルともに「都道府県コード」、「警察署等コード」、「本票番号」カラムを結合させてキーを作りたいと思います。
「事故番号」というカラムを作成します。
alter table honhyo_2019 add column 事故番号[text];
alter table kosokuhyo_2019 add column 事故番号[text];
以下で当該カラムに「都道府県コード」、「警察署等コード」、「本票番号」カラムの結合した文字列を格納します。
update honhyo_2019
set 事故番号 = 都道府県コード || 警察署等コード || 本票番号
update kosokuhyo_2019
set 事故番号 = 都道府県コード || 警察署等コード || 本票番号
これをキーとして使用したいと思います。
3.「honhyo_2019」テーブルの「路線コード」カラムを名称に変換
最初は「本票_路線コード」テーブルと結合して路線名を取得しようと思ったのですが、ちょっと困ったことに当該テーブルのレコードが以下のようになっていて結合ができないので、カラム追加をしてそこに路線名を格納しようと思います。

まずは「路線名」カラム追加します。
alter table honhyo_2019 add column 路線名[text];
次に追加したカラムに路線名を格納します。
update honhyo_2019
set 路線名 = case
when substr(路線コード,1,4) between '0001' and '0999' then '一般国道(国道番号)'
when substr(路線コード,1,4) between '1000' and '1499' then '主要地方道-都道府県道'
when substr(路線コード,1,4) between '1500' and '1999' then '主要地方道-市道'
when substr(路線コード,1,4) between '2000' and '2999' then '一般都道府県道'
when substr(路線コード,1,4) between '3000' and '3999' then '一般市町村道'
when substr(路線コード,1,4) between '4000' and '4999' then '高速自動車国道'
when substr(路線コード,1,4) between '5000' and '5499' then '自動車専用道-指定'
when substr(路線コード,1,4) between '5500' and '5999' then '自動車専用道-その他'
when substr(路線コード,1,4) between '6000' and '6999' then '道路運送法上の道路'
when substr(路線コード,1,4) between '7000' and '7999' then '農(免)道'
when substr(路線コード,1,4) between '8000' and '8499' then '林道'
when substr(路線コード,1,4) between '8500' and '8999' then '港湾道'
when substr(路線コード,1,4) between '9000' and '9499' then '私道'
when substr(路線コード,1,4) = '9500' then 'その他'
when substr(路線コード,1,4) = '9900' then '一般の交通の用に供するその他の道路'
end
これでデータの加工は終了です。
手順3(手順「2」で加工したデータをもとにシェープファイルに変換するデータを取得) サンプルコード
「honhyo_2019」「kosokuhyo_2019」テーブルから必要なカラムを選定し、コードを名称に変換します。
以下のSQLで取得するデータをシェープファイルに変換します(「手順4」参照)。カラム数がかなり多いので、必要最低限のカラムのみを取得しています。
select a.事故番号 as 事故番号,
c.都道府県名 as 都道府県,
e.区分 as 事故内容,
a.死者数 as 死者数,
a.負傷者数 as 負傷者数,
a.路線名 as 路線名,
a.発生日時 年 || '/' || a.発生日時 月 || '/' || a.発生日時 月 || ' ' || a.発生日時 時 || ':' ||a.発生日時 分 as 発生日時,
f.区分 as 天候,
g.区分 as 高速道路事故発生場所,
h.区分 as 道路構造,
a.地点 緯度(北緯) as 緯度,
a.地点 経度(東経) as 経度
from honhyo_2019 a
left outer join kosokuhyo_2019 b
on a.事故番号 = b.事故番号
left outer join 本票_補充票_高速票_都道府県コード c
on a.都道府県コード = c.コード
left outer join 本票_事故内容 e
on a.事故内容 = e.コード
left outer join 本票_天候 f
on a.天候 = f.コード
left outer join 高速票_道路区分 g
on b.道路区分 = g.コード
left outer join 高速票_道路構造 h
on b.道路構造 = h.コード
こんな感じのデータを取得することができました。
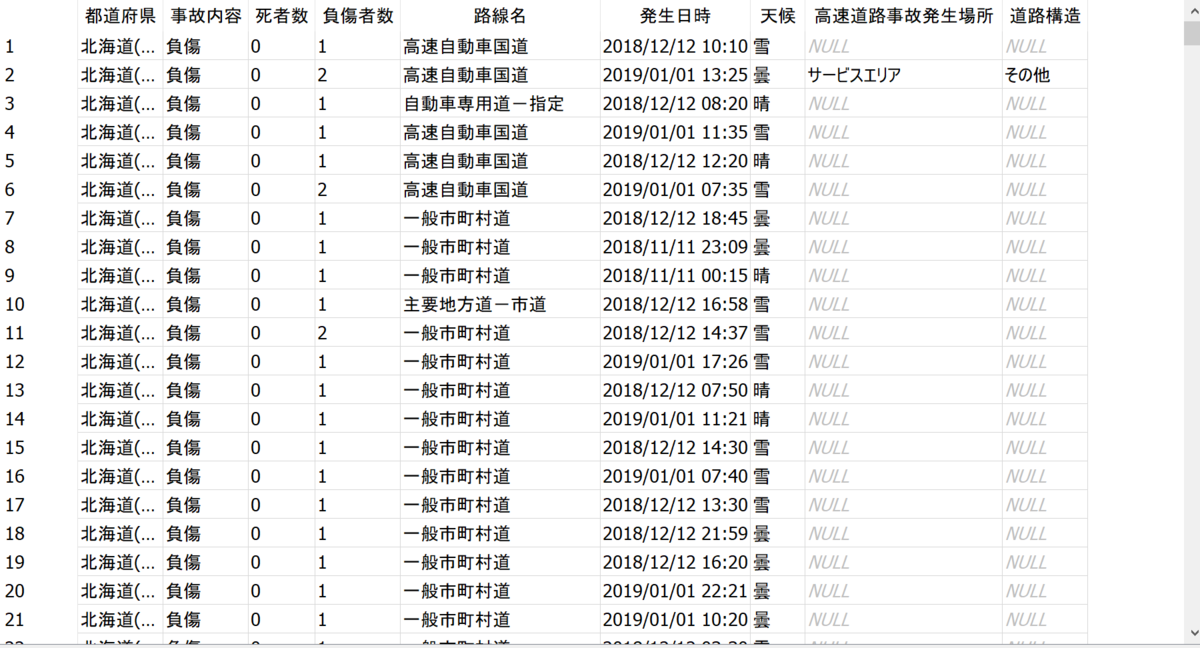
手順4(PyShp を使ってポイントのシェープファイルを作成) サンプルコード
「手順3」で使用している SQL を使用してポイントのシェープファイルを作成を作成します。PyShp に関しては以下のエントリーを参考にしてみてください。
www.gis-py.com
import math
from decimal import Decimal, ROUND_HALF_UP
from os.path import join
import sqlite3
import shapefile
import pandas as pd
shape_path = r"D:\blog\data\shape"
db_path = r"D:\blog\data\sqlite\test.db"
epsg = 'GEOGCS["WGS 84",DATUM["WGS_1984",SPHEROID["WGS 84",6378137,298.257223563]],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433]]'
def dms2deg(dms):
"""緯度経度を度分秒から度へ変換します"""
h = dms[0]
m = dms[1]
s = dms[2]
deg = Decimal(str(int(h) + (int(m) / 60) + (float(s) / 3600))).quantize(Decimal('0.0001'), rounding=ROUND_HALF_UP)
return deg
def get_data():
"""SQLiteからデータを取得します"""
conn = sqlite3.connect(db_path)
sql = """select a.事故番号 as 事故番号,
c.都道府県名 as 都道府県,
e.区分 as 事故内容,
a.死者数 as 死者数,
a.負傷者数 as 負傷者数,
a.路線名 as 路線名,
a.発生日時 年 || '/' || a.発生日時 月 || '/' || a.発生日時 月 || ' ' || a.発生日時 時 || ':' ||a.発生日時 分 as 発生日時,
f.区分 as 天候,
g.区分 as 高速道路事故発生場所,
h.区分 as 道路構造,
a.地点 緯度(北緯) as 緯度,
a.地点 経度(東経) as 経度
from honhyo_2019 a
left outer join kosokuhyo_2019 b
on a.事故番号 = b.事故番号
left outer join 本票_補充票_高速票_都道府県コード c
on a.都道府県コード = c.コード
left outer join 本票_事故内容 e
on a.事故内容 = e.コード
left outer join 本票_天候 f
on a.天候 = f.コード
left outer join 高速票_道路区分 g
on b.道路区分 = g.コード
left outer join 高速票_道路構造 h
on b.道路構造 = h.コード
"""
return pd.read_sql_query(sql=sql, con=conn)
def create_shape():
"""シェープファイルを作成します"""
df = get_data()
column_list = df.columns.values
with shapefile.Writer(join(shape_path, "traffic_data.shp")) as w:
for column in column_list:
if column == "緯度":
w.field(column, "F", 18, 8)
elif column == "経度":
w.field(column, "F", 18, 8)
else:
w.field(column, "C", 100)
for _, row in df.iterrows():
lat = 0
lon = 0
attributes = []
for column in column_list:
if column == "緯度":
lat = row[column]
lat = dms2deg((lat[0:2], lat[2:4], lat[4:6] + "." + lat[6:]))
attributes.append(lat)
elif column == "経度":
lon = row[column]
lon = dms2deg((lon[0:3], lon[3:5], lon[5:7] + "." + lon[7:]))
attributes.append(lon)
else:
if row[column] == None:
attributes.append("")
else:
attributes.append(row[column])
w.point(float(lon), float(lat))
w.record(attributes[0],attributes[1],attributes[2],attributes[3],
attributes[4],attributes[5],attributes[6],attributes[7],
attributes[8],attributes[9],attributes[10],attributes[11])
with open("%s.prj" % join(shape_path, "traffic_data"), "w") as prj:
prj.write(epsg)
if __name__ == '__main__':
create_shape()
このようにシェープファイルが作成されていることが確認できました。やはり件数が多いだけあって容量が大きいですね。
手順5(ArcGIS Online で可視化)
シェープファイル を ArcGIS Online にアップロードしてみます。
ArcGIS Online の使い方に関してはESRIジャパンさんが主催した「ArcGIS 開発者のための最新アプリ開発塾 2020」の「Web GIS 基礎 ~ArcGIS Online を使ってみよう!~」を参考にしてみてください。
community.esri.com
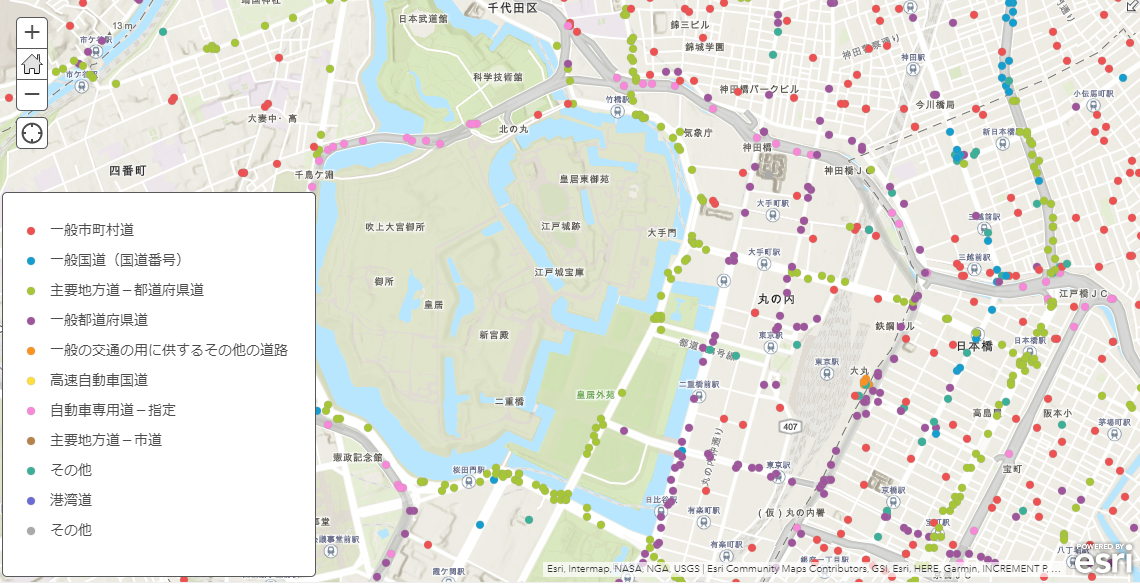
路線ごとに色分けした結果を表示してみました。正しくデータがプロットされていることがわかります。
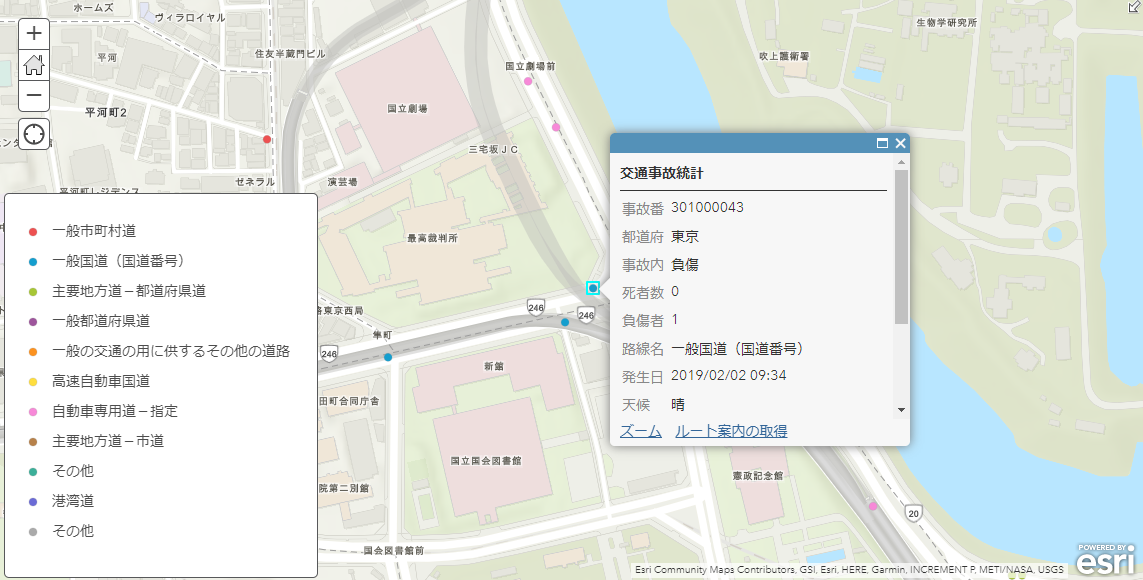
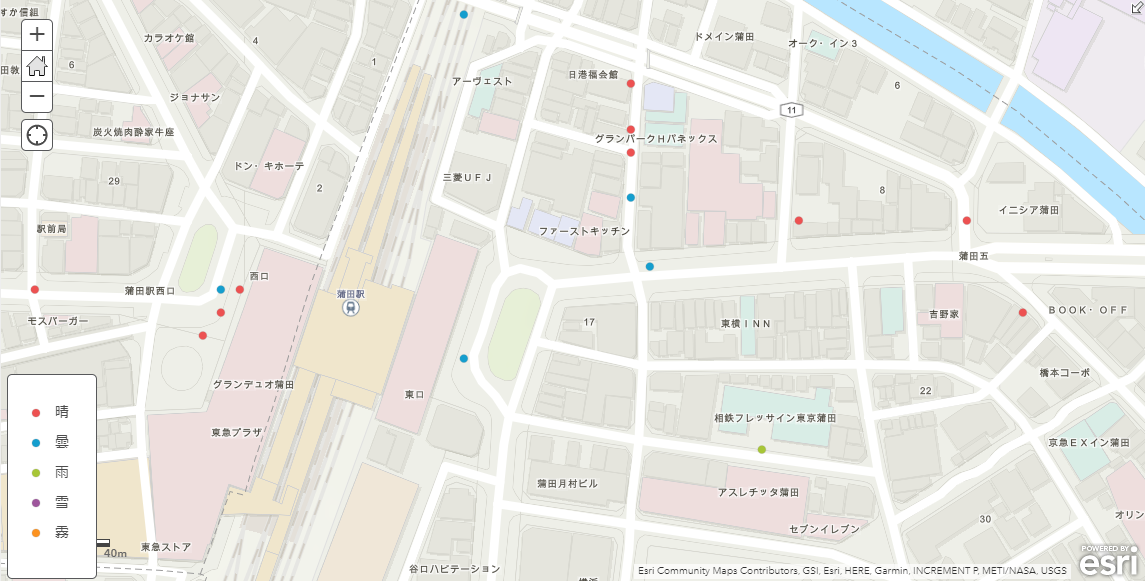
天候ごとにも色分けしてみました。
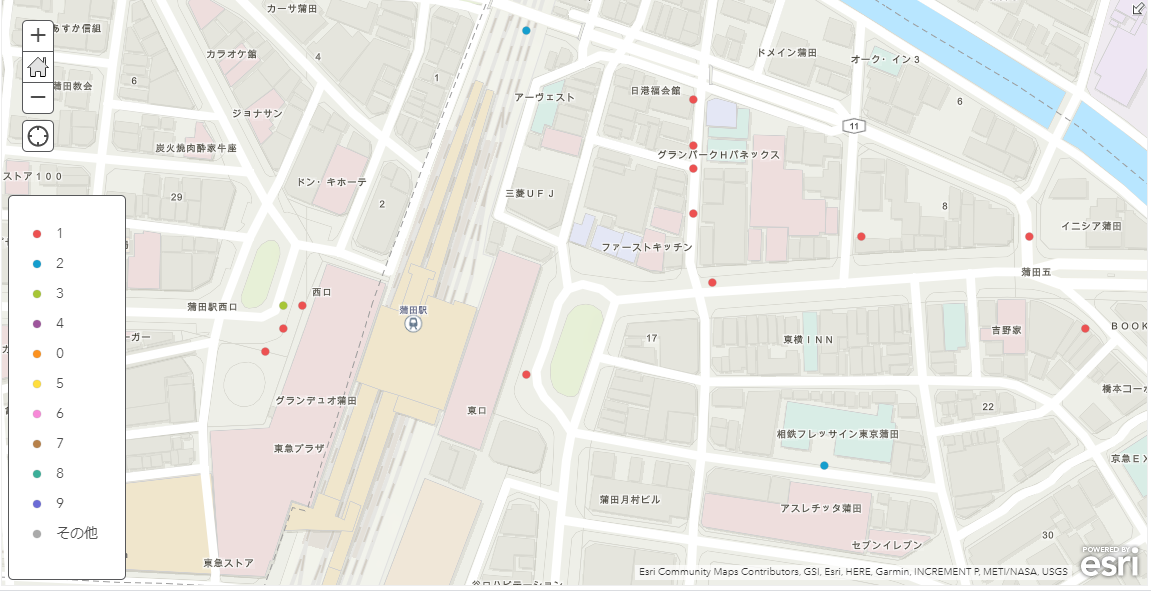
事故ごとの負傷者数で色分けなんかもできます。
データをより細かく分析するにはどうしたらいいのか?
以下のようなことがしたい場合は ArcGIS Pro などのデスクトップアプリケーションを導入することをお勧めします。
- 事故多発地帯の分析
- 同じ地点に短期間限定で事故が多発している箇所の分析
- 天候ごとに事故が発生しやすい箇所の分析
- etc
さいごに
オープンデータにありがちですが、データが素直に取り込めばいいという状態になっておらず色々苦労しました。交通事故統計データだけでなく、日本のオープンデータすべてが利用者にとってもう少し優しい形になってほしいですね。
手順が多いエントリーになってしまいましたが、何とか交通事故統計データの可視化までもっていくことができました。ただ、GIS的にはここからが本番でデータ分析してこそ、そのデータに価値が生まれるかと思います。もし ArcGIS Pro でこのデータを使った分析方法を知りたいという方がいらっしゃいましたら本エントリーにコメントを残していただければと思います。
本エントリーが今年最後です。今年もありがとうございました。来年もよろしくお願いします。それではよいお年をお迎えください。