さて、本日は気象庁の HP から気象データをスクレイピングしようと思います。
スクレイピングとは
ウェブスクレイピングとは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。ウェブ・クローラーあるいはウェブ・スパイダーとも呼ばれる。 通常このようなソフトウェアプログラムは低レベルのHTTPを実装することで、もしくはウェブブラウザを埋め込むことによって、WWWのコンテンツを取得する。(出典:Wikipedia)
関連エントリー
過去のエントリーで他サイトのスクレイピングについて書いていますので興味のある方はぜひ参考にしてみてください。
事の発端
以下のサイトから東京の一時間ごとの気象データをダウンロードしようとしたのですが、一回のダウンロードの容量制限があり数年間分のデータをダウンロードするのは少し面倒だなと思い今回のエントリーに至りました。

スクレイピングするサイト
上記のダウンロードサイトではなく過去の気象データ検索のサイトを利用してスクレイピングを行おうと思います。

使用するライブラリ
Beautiful Soup というライブラリを使用します。Beautiful Soupは、HTMLおよびXMLドキュメントを解析するためのPythonパッケージです。 HTMLからデータを抽出するために使用できる解析済みページの解析ツリーを作成します。これはWebスクレイピングに役立ちます。(出典:Wikipedia)
ダウンロードするデータ
今回は以下データをダウンロードします。場所、期間を変えたいという方は掲載するサンプルコードを少し変えれば問題ないかと思います。ただ、データの単位を変えたい場合は少し工夫が必要になりますが今回はそれについては割愛します。
- 場所・・・東京
- 期間・・・2016年~2020年
- データの単位・・・時間ごと
環境
Windows10 64bit
Python3.8.5
サンプルコード
気象データをスクレイピングするサンプルコードです。
# -*- coding: utf-8 -*- import os import datetime import csv import urllib.request from bs4 import BeautifulSoup def str2float(weather_data): try: return float(weather_data) except: return 0 def scraping(url, date): # 気象データのページを取得 html = urllib.request.urlopen(url).read() soup = BeautifulSoup(html) trs = soup.find("table", { "class" : "data2_s" }) data_list = [] data_list_per_hour = [] # table の中身を取得 for tr in trs.findAll('tr')[2:]: tds = tr.findAll('td') if tds[1].string == None: break; data_list.append(date) data_list.append(tds[0].string) data_list.append(str2float(tds[1].string)) data_list.append(str2float(tds[2].string)) data_list.append(str2float(tds[3].string)) data_list.append(str2float(tds[4].string)) data_list.append(str2float(tds[5].string)) data_list.append(str2float(tds[6].string)) data_list.append(str2float(tds[7].string)) data_list.append(str2float(tds[8].string)) data_list.append(str2float(tds[9].string)) data_list.append(str2float(tds[10].string)) data_list.append(str2float(tds[11].string)) data_list.append(str2float(tds[12].string)) data_list.append(str2float(tds[13].string)) data_list_per_hour.append(data_list) data_list = [] return data_list_per_hour def create_csv(): # CSV 出力先ディレクトリ output_dir = r"D:\blog\data\weather" # 出力ファイル名 output_file = "weather.csv" # データ取得開始・終了日 start_date = datetime.date(2016, 1, 1) end_date = datetime.date(2020, 12, 31) # CSV の列 fields = ["年月日", "時間", "気圧(現地)", "気圧(海面)", "降水量", "気温", "露点湿度", "蒸気圧", "湿度", "風速", "風向", "日照時間", "全天日射量", "降雪", "積雪"] # 天気、雲量、視程は今回は対象外とする with open(os.path.join(output_dir, output_file), 'w') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(fields) date = start_date while date != end_date + datetime.timedelta(1): # 対象url(今回は東京) url = "http://www.data.jma.go.jp/obd/stats/etrn/view/hourly_s1.php?" \ "prec_no=44&block_no=47662&year=%d&month=%d&day=%d&view="%(date.year, date.month, date.day) data_per_day = scraping(url, date) for dpd in data_per_day: writer.writerow(dpd) date += datetime.timedelta(1) if __name__ == '__main__': create_csv()
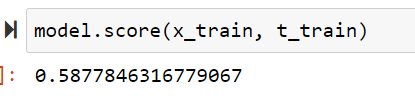
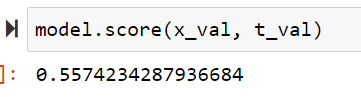
やはり少々データ量が多いだけあって処理完了まで少しだけ時間がかかりました。ただ、結果はばっちりですね!


さいごに
気象庁のデータのダウンロードページは便利なのですが、様々な場所のデータを数年間分欲しいといった場合に手動でダウンロードを行うというのはあまり現実ではないかと思います。その際に本エントリーで紹介したようなスクレイピングが役に立つかと思います。また、世の中にある様々な Web サイトのデータ(例:食べログ)がほしいといった場合もスクレイピングをすることで今回のようにデータを取得することができます。興味のある方はぜひチャレンジしてみてください!本日は以上です。